Overview
As a Business and Technology Consulting firm, many of our clients have built out environments that support analytics, however some work better than others. This Point of View whitepaper will discuss some of their processing challenges and how we solve them with intelligent design and a shift of technology in a software defined storage world.
The Issue
Destiny Corporation specializes in infrastructure that supports analytics. Many clients from Fortune 500 to medium businesses and the government are all jumping on the analytics bandwagon with larger amounts of data than ever before. If the infrastructure was not designed properly, the Analysts and Data Scientists will know as soon as they use the environment. Infrastructure only matters when it does not work properly.
In our professional opinion, assuming an environment is stable, which can be its own challenge, the simplest test of how well a system is operating, with its combined parts of storage, GPU, CPU, network, memory and so on is to look at the speed of processes and any potential bottlenecks. These are usually found in I/O that can come in many forms. The most common one we see is slowdown in processing because the data cannot get on and off disk fast enough. However, when issues with disk are resolved, I/O bottlenecks can turn up in other computing areas. The question to all of this is ‘does it really matter?’ Are the analysts really satisfied with jobs taking multiple hours to complete vs. a few minutes? What would they be able to accomplish with the extra time and faster speed of processing? This may be more of a rhetorical management question. What if the IT infrastructure that supports them did not have to be so large?
Another topic we consistently hear from clients is ‘how can I get to all of my data when, where, and in the form I need?’ There are many perspectives that make answering this question rather complex. The first is where is the data? Is it stored on a mainframe, Posix compliant architecture, SAN, NAS, Hadoop, Cloud, object, another server, external disk, and so on? The second is what is the access method? Is it direct attached, NFS mount, fiber, Ethernet, database, tape, cloud, etc.? Third, what is the security protocol around access and how will authorization work? Fourth, where will the processing take place? Will we use a federated style micro service to process where the data lives or must we drag it over to our processing server? For example, what if I want to process data on a high powered AIX or Linux on Power server and then give access to the same data from Windows? Finally, how do we handle the changing needs of our storage? These are all standard requests from clients, and they are all solvable.
Current Architectures
Many current analytic architectures are designed around the number of CPUs available on the servers for processing. As this is the standard pricing from many software vendors, it makes sense and is a simple measurement. More CPUs mean more cost for software. However, some software and database vendors base their costs on the amount of storage. As of the time of this writing, we have not found any who concentrate on the quality and speed of the storage infrastructure. In addition, many large organizations have a complex array of storage types and vendors, several of which were fit for purpose at the time of purchase, but have gone under or over utilized through time.
Many traditional storage architectures are based on some level of hard wired direct attached, InfiniBand, or network connection, whether it be on-prem or in the cloud. It is the hardwired nature of traditional storage that has not only introduced limitations, but created bad behavior such as using NFS mounts to transfer massive amounts of data.
Heat Maps
Having a whole bunch of spindles configured on a platter is great, but the usage of the storage requires understanding. For email, having numerous single threaded messages that need to be accessed by the organization may be one type of use. However, analytics processing that may entail large amounts of data may be hampered by storage designed for Microsoft Word documents. Smart analytics processes and databases that utilize multiple threads, sharding, and other techniques require storage that can work together in concert taking in or serving up data. In many of our consulting assignments where there are storage bottlenecks, we routinely ask to see what disks are active during these types of concurrent queries. Quite often we find a small section of platters is active, while the rest remain underutilized. Heat map reports offered by some vendors are a way of quickly determining what is actually going on as the graphs can show the red, yellow, and green style traffic lighting of the disk activity. The challenge is that so many storage vendors do not know how to configure their own systems to handle multiple, concurrent full table scans performed by analytics users.
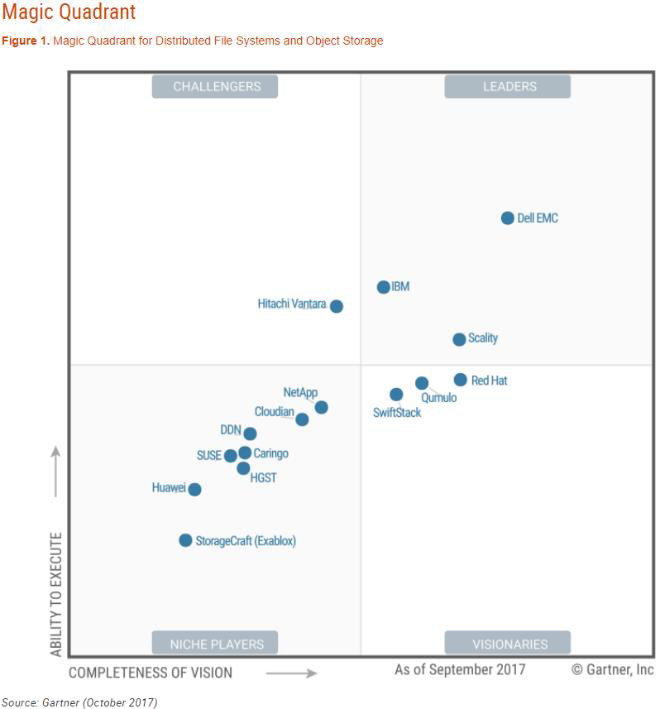
Gartner’s Opinion vs. Actual Experience
Gartner is a great research organization and helps its’ members determine what is happening with technology in their respective industries. However, we do not believe that Gartner works in the trenches of IT projects. The Gartner graph republished in this paper show Dell EMC and IBM being industry leaders in this space. However, this represents sales of this type of equipment. Gartner also talks about how popular Isilon is for storage. While it is a great platform for many standard uses, it is one of several platforms that we have seen cause bottlenecks when it comes to the ability to support high, concurrent analytics workloads with sustained I/O throughput. Many of our clients have relegated this type of storage for other uses within the organization, replacing it with systems designed for much higher throughput. It is important to think about the interpretation of the Magic Quadrant.
See Appendix A
New Architectures
In our new world, we look at implementing all of the capabilities of managing data storage in software as we abstract it from the heterogeneous hardware layer. While Software Defined Storage is being supported by various vendors, a closer look shows what works well for analytics processing.
In our experience, when clients have issues with performing analytics on data in heterogeneous storage environments, multiple operating systems, and various databases or storage formats, such as Hadoop, they turned to IBM’s GPFS (General Parallel File System), now known as Spectrum Scale. For years, clients have used this software as the secret sauce that connected their storage infrastructure. Today, IBM has developed their Elastic Storage Server environment, which is based on Spectrum Scale and many other SDS capabilities including parallel file systems, redundant storage, global name spaces, policy based tiering, creation of snapshots, data encryption, replication and support of disaster recovery. ESS, with its Spectrum Scale capability can easily augment and manage data in corporate environments.
We find this interesting for several reasons, many of which support IT’s objectives, but also the ability to improve analytics environments, in not only a Power, but an x86 world. Let’s discuss a curious IT initiative. While Hadoop’s original recommendation of keeping three copies of the data was a standard for so many years, astute organizations quickly learned that by using Spectrum Scale under the covers, this was not required. This means a large Hadoop storage shop having ten TBs of raw storage, with only three usable could implement Spectrum Scale and utilize ten TBs of storage. There is a slight caveat. Some Hadoop vendors say they will not support this, however, we found that if you are a large enough client, they actually will.
For our analytics friends that bought into the belief that commodity x86 hardware is what the software vendor recommends and if processing is slow, just buy more x86 servers, we have a solution. In previous articles, we wrote about the x86 challenge when it comes to heavy analytics. The fact is that x86 design should not be governed by I/O constraints, which normally occur at the storage level. Therefore, in new architectures that use Ethernet based storage topologies running at 40Gb, 56Gb, and 100Gb, it is now possible to give the servers all the throughput they need for processing, removing the storage based I/O bottleneck. In a recent installation tested by IBM, an ESS environment with a Mellanox switch backbone was able to support thousands of server workloads without issue. The movement of such large amounts of analytical data via the IP (Internet Protocol) consumes a large amount of CPU resources. For every 10GBps of throughput, 4 to 5 cores of x86 are required. However, the same throughput is achieved with 2 cores of Power, less than half the x86 requirement. This is why IBM uses Power in their configurations for a much better architecture.

By separating storage capabilities from the underlying hardware, SDS adds the flexibility and agility to granularly control how storage supports each part of the infrastructure.
Source: IBM
Client Reference
A year ago, a new x86 grid based analytics environment was designed and built by the IT folks of a large firm. The software vendor recommended many commodity x86 servers. Once the environment was up and began to take on significant workload, the grid environment performed even worse than the original environment used by the analytics folks. IT did not understand why. A year later, IBM came in and looked at the issue. They installed an ESS environment and effectively removed the storage based I/O bottleneck. Processing all of the jobs was much faster until, after hitting their full capacity, the x86 servers became the new I/O bottleneck. This gave the client the opportunity to increase its throughput as they purchased more servers and looked for alternative scale up architecture. The result? The IT department was relieved to see their already installed x86 environment performed much better with faster analytics processing. However, future purchases will be made with a more informed understanding of analytics workloads that will drive proper architecture design. They learned that scale out with commodity processors could not handle their storage I/O workloads efficiently on their own.
Summary
In closing, because of the increase in the amount of data available for analytics processing, the new methodologies for using the data, and the desire to harness these technologies and stay ahead of the competition, it is a whole new world out there. At Destiny Corporation, we always knew that storage played a major role in how well analytic environments process. However, the designs we would have recommended just a few years ago are not what we discuss with our clients today. The technology has changed along with the requirement and flexibility to get at data, no matter where it lives. Data should be able to process on any desired system, and not be constrained by poorly designed and utilized storage environments.
Appendix A